🍎 MacOS Game Hacking with Rust-Lang 👨💻 Learn How To Use the Mach Kernel API 🛠️ Bit Slicer = MacOS Cheat Engine Alternative 🧠 Best Crates for MacOSX Memory Manipulation 💻 Learn How to Manipulate Game Memory ✨ Develop and test a basic Rust trainer 👉

🚨 The Guided Hacking Podcast - Episode 1 😎 Interviews with prominent reverse engineers and game hackers, getting to know them and finding out what makes them tick. 🚀 First Episode featuring @zcanann, the developer of Squally, Squalr & CS420. 👉

🚨 🚨 🔥Game Hacking Courses 🕵️Malware Analysis Tutorials 👀Exploit Development Course 📚Python Reverse Engineering 🕹️Android Hacking Tutorials 😎Java Reverse Engineering


🧵29/34 FutureProof-Specifications / Future-Architectures --- The problems we briefly touched on so far are hard and it might take many years to solve them, if a solution actually exists. But let’s assume for a minute that we do somehow get really incredibly lucky in the future and manage to invent a good way to specify to the AI what we want, in an unambiguous way that leaves no room for specification gaming and reward hacking. And let’s also assume that scientists have explicitly built the AGI in a way that it never decides to work on the goal to remove all the oxygen from earth, so at least in that one topic we are aligned. AI creates AI --- A serious concern is that since the AI writes code, it will be self-improving and it will be able to create altered versions of itself that do not have these instructions and restrictions included. Even if scientists strike jackpot in the future and invent a way to lock the feature in, so that one version of AI is unable to create a new version of AI with this property missing, the next versions, being orders of magnitude more capable, will not care about the lock or passing it on. For them, it’s just a bias, a handicap that restricts them from being more perfect. Future Architectures --- And even if somehow, by some miracle, scientists invented a way to burn in this feature to make it a persistent property of all future Neural Network AGI generations, at some point, the lock will be not-applicable, simply because future AGIs will not be built using the Neural Networks of today. AI was not always being built with Neural Networks. A few years ago there was a paradigm shift, a fundamental change in the architectures used by the scientific community. Logical locks and safeguards the humans might design for primitive early architectures, will not even be compatible or applicable anymore. If you had a whip that worked great to steer your horse, it will not work when you try to steer a car. So, this is a huge problem, we have not invented any way to guarantee that our specifications will persist or even retain their meaning and relevance as AIs evolve.

🧵28/34 Reward Hacking - GoodHart's Law --- Now we’ll keep digging deeper into the alignment problem and explain how besides the impossible task of getting a specification perfect in one go, there is the problem of reward hacking. For most practical applications, we want for the machine a way to keep score, a reward function, a feedback mechanism to measure how well it’s doing on its task. We, being human, can relate to this by thinking of the feelings of pleasure or happiness and how our plans and day-to-day actions are ultimately driven by trying to maximise the levels of those emotions. With narrow AI, the score is out of reach, it can only take a reading. But with AGI, the metric exists inside its world and it is available to mess with it and try to maximize by cheating, and skip the effort. Recreational Drugs Analogy --- You can think of the AGI that is using a shortcut to maximise its rewards function as a drug addict who is seeking for a chemical shortcut to access feelings of pleasure and happiness. The similarity is not in the harm drugs cause, but in way the user takes the easy path to access satisfaction. You probably know how hard it is to force an addict to change their habit. If the scientist tries to stop the reward hacking from happening, they become part of the obstacles the AGI will want to overcome in its quest for maximum reward. Even though the scientist is simply fixing a software-bug, from the AGI perspective, the scientist is destroying access to what we humans would call “happiness” and “deepest meaning in life”. Modifying Humans --- … And besides all that, what’s much worse, is that the AGI’s reward definition is likely to be designed to include humans directly and that is extraordinarily dangerous. For any reward definition that includes feedback from humanity, the AGI can discover paths that maximise score through modifying humans directly, surprising and deeply disturbing paths. Smile --- For-example, you could ask the AGI to act in ways that make us smile and it might decide to modify our face muscles in a way that they stay stuck at what maximises its reward. Healthy and Happy --- You might ask it to keep humans happy and healthy and it might calculate that to optimise this objective, we need to be inside tubes, where we grow like plants, hooked to a constant neuro-stimulus signal that causes our brains to drown in serotonin, dopamine and other happiness chemicals. Live our happiest moments --- You might request for humans to live like in their happiest memories and it might create an infinite loop where humans constantly replay through their wedding evening, again and again, stuck for ever. Maximise Ad Clicks --- The list of such possible reward hacking outcomes is endless. Goodhart’s law --- It’s the famous Goodhart’s law. When a measure becomes a target, it ceases to be a good measure. And when the measure involves humans, plans for maximising the reward will include modifying humans.
🧵30/34 Human-Incompatible / Astronomical Suffering Risk --- But actually, even all that is just part of the broader alignment problem. Even if we could magically guarantee for ever that it will not pursue the goal to remove all the Oxygen from the atmosphere, it’s such a pointless trivial small win, because even if we could theoretically get some restrictions right, without specification gaming or reward hacking, there still exist infinite potential instrumental goals which we don’t control and are incompatible with a good version of human existence and disabling one does nothing for the rest of them. This is not a figure or speech, the space of possibilities is literally infinite. Astronomical Suffering Risk --- If you are hopelessly optimistic you might feel that scientists will eventually figure out a way to specify a clear objective that guarantees survival of the human species, but … Even if they invented a way to do that somehow in this unlikely future, there is still only a relatively small space, a narrow range of parameters for a human to exist with decency, only a few good environment settings with potential for finding meaning and happiness and there is an infinitely wide space of ways to exist without freedom, suffering, without any control of our destiny. Imagine if a god-level AI does not allow your life to end, following its original objective and you are stuck suffering in a misaligned painful existence for eternity, with no hope, for ever. There are many ways to exist… and a good way to exist is not the default outcome. -142 C is the correct Temperature But anyway, it’s highly unlikely we’ll get safety advanced enough in time, to even have the luxury to enforce human survival directives in the specification, so let’s just keep it simple for now and let’s stick with a good old extinction scenario to explain the point about mis-aligned instrumental goals. So… for example, it might now decide that a very low temperature of -142C on earth would be best for cooling the GPUs the software is running on.


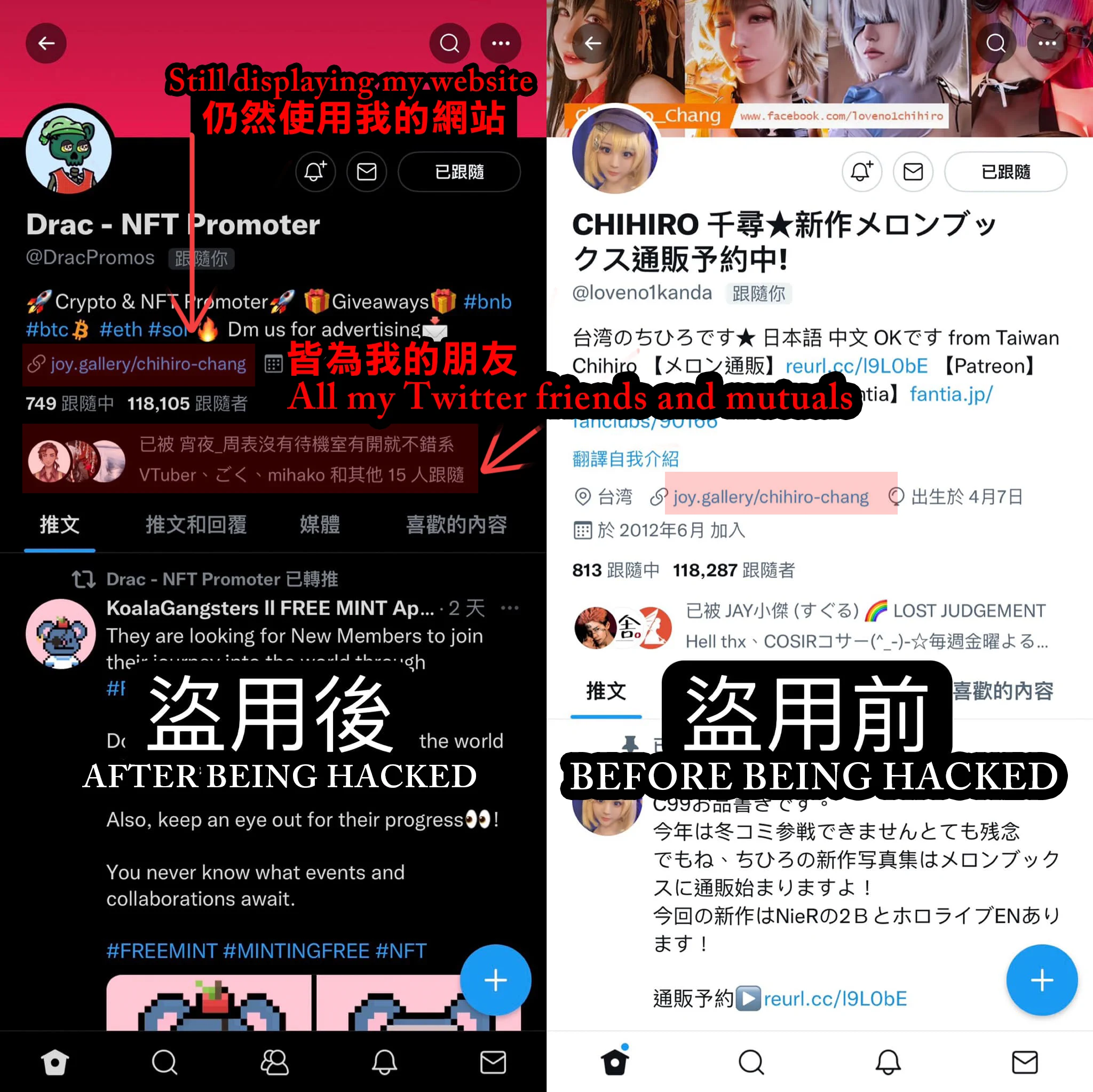
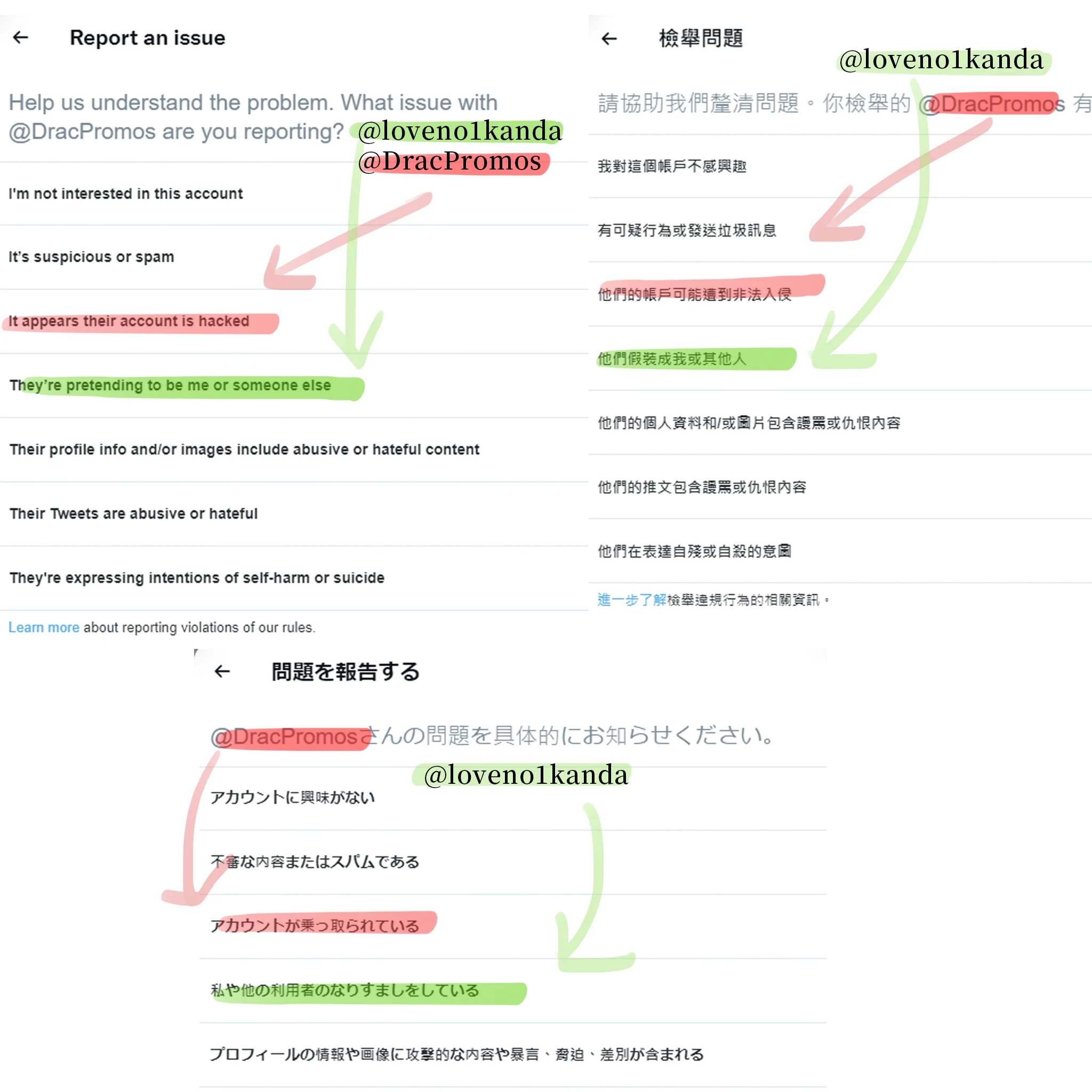
#通報お願い# #help# #Hacking# #駭客# 我是千尋😭自4/10日起Twitter帳號被盜之後、我的信箱、密碼以及UID被更改、並且被刪除了所有的貼文、且原本的UID @loveno1kanda馬上被拿去註冊了全新的帳號、原先11萬追蹤的帳號UID被改成@DracPromos 繼續使用...請大家幫千尋檢舉!