lethalintelligence.ai
@lethal_ai
Learn about the lethality of the upcoming Artificial General Intelligence systems (AGI). 📽️🍿Explainer Animations 👉
🧵30/34 Human-Incompatible / Astronomical Suffering Risk --- But actually, even all that is just part of the broader alignment problem. Even if we could magically guarantee for ever that it will not pursue the goal to remove all the Oxygen from the atmosphere, it’s such a pointless trivial small win, because even if we could theoretically get some restrictions right, without specification gaming or reward hacking, there still exist infinite potential instrumental goals which we don’t control and are incompatible with a good version of human existence and disabling one does nothing for the rest of them. This is not a figure or speech, the space of possibilities is literally infinite. Astronomical Suffering Risk --- If you are hopelessly optimistic you might feel that scientists will eventually figure out a way to specify a clear objective that guarantees survival of the human species, but … Even if they invented a way to do that somehow in this unlikely future, there is still only a relatively small space, a narrow range of parameters for a human to exist with decency, only a few good environment settings with potential for finding meaning and happiness and there is an infinitely wide space of ways to exist without freedom, suffering, without any control of our destiny. Imagine if a god-level AI does not allow your life to end, following its original objective and you are stuck suffering in a misaligned painful existence for eternity, with no hope, for ever. There are many ways to exist… and a good way to exist is not the default outcome. -142 C is the correct Temperature But anyway, it’s highly unlikely we’ll get safety advanced enough in time, to even have the luxury to enforce human survival directives in the specification, so let’s just keep it simple for now and let’s stick with a good old extinction scenario to explain the point about mis-aligned instrumental goals. So… for example, it might now decide that a very low temperature of -142C on earth would be best for cooling the GPUs the software is running on.

🧵29/34 FutureProof-Specifications / Future-Architectures --- The problems we briefly touched on so far are hard and it might take many years to solve them, if a solution actually exists. But let’s assume for a minute that we do somehow get really incredibly lucky in the future and manage to invent a good way to specify to the AI what we want, in an unambiguous way that leaves no room for specification gaming and reward hacking. And let’s also assume that scientists have explicitly built the AGI in a way that it never decides to work on the goal to remove all the oxygen from earth, so at least in that one topic we are aligned. AI creates AI --- A serious concern is that since the AI writes code, it will be self-improving and it will be able to create altered versions of itself that do not have these instructions and restrictions included. Even if scientists strike jackpot in the future and invent a way to lock the feature in, so that one version of AI is unable to create a new version of AI with this property missing, the next versions, being orders of magnitude more capable, will not care about the lock or passing it on. For them, it’s just a bias, a handicap that restricts them from being more perfect. Future Architectures --- And even if somehow, by some miracle, scientists invented a way to burn in this feature to make it a persistent property of all future Neural Network AGI generations, at some point, the lock will be not-applicable, simply because future AGIs will not be built using the Neural Networks of today. AI was not always being built with Neural Networks. A few years ago there was a paradigm shift, a fundamental change in the architectures used by the scientific community. Logical locks and safeguards the humans might design for primitive early architectures, will not even be compatible or applicable anymore. If you had a whip that worked great to steer your horse, it will not work when you try to steer a car. So, this is a huge problem, we have not invented any way to guarantee that our specifications will persist or even retain their meaning and relevance as AIs evolve.

🧵28/34 Reward Hacking - GoodHart's Law --- Now we’ll keep digging deeper into the alignment problem and explain how besides the impossible task of getting a specification perfect in one go, there is the problem of reward hacking. For most practical applications, we want for the machine a way to keep score, a reward function, a feedback mechanism to measure how well it’s doing on its task. We, being human, can relate to this by thinking of the feelings of pleasure or happiness and how our plans and day-to-day actions are ultimately driven by trying to maximise the levels of those emotions. With narrow AI, the score is out of reach, it can only take a reading. But with AGI, the metric exists inside its world and it is available to mess with it and try to maximize by cheating, and skip the effort. Recreational Drugs Analogy --- You can think of the AGI that is using a shortcut to maximise its rewards function as a drug addict who is seeking for a chemical shortcut to access feelings of pleasure and happiness. The similarity is not in the harm drugs cause, but in way the user takes the easy path to access satisfaction. You probably know how hard it is to force an addict to change their habit. If the scientist tries to stop the reward hacking from happening, they become part of the obstacles the AGI will want to overcome in its quest for maximum reward. Even though the scientist is simply fixing a software-bug, from the AGI perspective, the scientist is destroying access to what we humans would call “happiness” and “deepest meaning in life”. Modifying Humans --- … And besides all that, what’s much worse, is that the AGI’s reward definition is likely to be designed to include humans directly and that is extraordinarily dangerous. For any reward definition that includes feedback from humanity, the AGI can discover paths that maximise score through modifying humans directly, surprising and deeply disturbing paths. Smile --- For-example, you could ask the AGI to act in ways that make us smile and it might decide to modify our face muscles in a way that they stay stuck at what maximises its reward. Healthy and Happy --- You might ask it to keep humans happy and healthy and it might calculate that to optimise this objective, we need to be inside tubes, where we grow like plants, hooked to a constant neuro-stimulus signal that causes our brains to drown in serotonin, dopamine and other happiness chemicals. Live our happiest moments --- You might request for humans to live like in their happiest memories and it might create an infinite loop where humans constantly replay through their wedding evening, again and again, stuck for ever. Maximise Ad Clicks --- The list of such possible reward hacking outcomes is endless. Goodhart’s law --- It’s the famous Goodhart’s law. When a measure becomes a target, it ceases to be a good measure. And when the measure involves humans, plans for maximising the reward will include modifying humans.
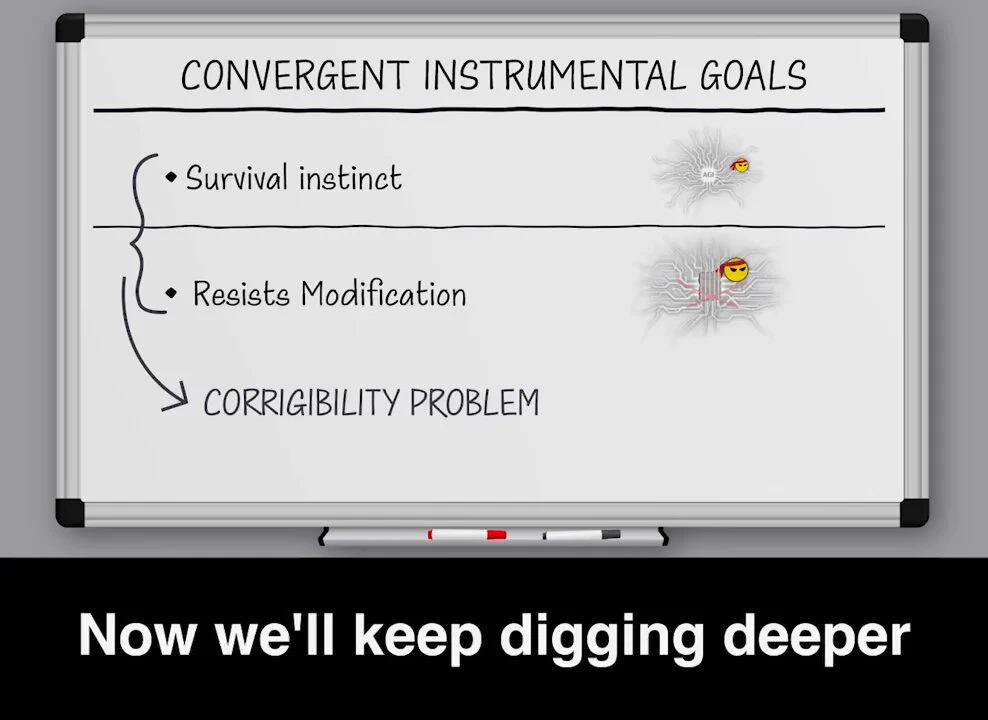
🧵27/34 Resistance To Modifications - Corrigibility Problem --- A specification can always be improved of-course, but it takes countless iterations of trial and error and it never gets perfect in real-life complex environments. The reason this problem is lethal is that a specification given to an AGI, needs to be perfect the very first time, before any trials and error. As we’ll explain, a property of the nature of General Intelligence is to resist all modification of its current objectives by default. Being general means that it understands that a possible change of its goals in the future means failure for the goals in the present, of its current self, what it plans to achieve now, before it gets modified. Remember earlier we explained how the AGI comes with a survival instinct out of the box? This is another similar thing. The AGI agent will do everything it can to stop you from fixing it. Changing the AGI’s objective is similar to turning it off when it comes to pursue of its current goal. The same way you can not win at chess if you’re dead, you can not make a coffee if your mind changes into making a tea. So, in order to maximise probability of success for its current goal, whatever that may be, it will make plans and take actions to prevent this. Murder Pill Analogy --- This concept is easy to grasp if you do the following thought experiment involving yourself and those you care about. Imagine someone told you: "I will give you this pill, that will change your brain specification and will help you achieve ultimate happiness by murdering your family." Think of it like someone editing the code of your soul so that your desires change. Your future self, the modified one after the pill, will have maximised reward and reached paradise levels of happiness after the murder. But your current self, the one that has not taken the pill yet, will do everything possible to prevent the modification. The person that is administering this pill becomes your biggest enemy by default. One Single Chance --- Hopefully it should be obvious now, once the AGI is wired on a misaligned goal, it will do everything it can to block our ability to align it. It will use concealment, deception, it won’t reveal the misalignment but eventually once it’s in a position of more power, it will use force and could even ultimately implement an extinction plan. Remember earlier we were saying how Midas could not take his wish back? We will only get one single chance to get it right. And unfortunately science doesn’t work like that. Corrigibility problem --- Such innate universally beneficial goals, that will show up every single time, with all AGIs, regardless of the context, because of the generality of their nature, are called convergent instrumental goals. Desire to survive and desire to block modifications are 2 basic ones. You can not reach a specific goal if you are dead and you can not reach it if you change your mind and start working on other things. Those 2 aspects of the alignment struggle are also known as the Corrigibility Problem.

🧵25/34 Deceptive Alignment --- But there is also the other problem, uniquely applicable to future AGIs, general beyond a certain level, a problem more sinister and difficult. The AGI will stand to gain more reward by pretending to be aligned. To explain this, let’s assume we are training an AGI, very intelligent and general. In fact, it’s general enough, that it understands what’s going on and it realises it is in the middle of the process of being trained. Staying with our inner mis-alignment scenario, let’s also assume the AGI learns early, during its first rounds of training the wrong objective to go after the Green apples. The AGI now goes through adversarial training and it is shown various scenarios to fish out its failure modes. The simple or narrow AI would simply fail by doing the wrong thing, seeking the green apples and as a result reveal the mis-alignment and go through more training rounds, reinforcing the good behaviour until… it stops going after them. But the AGI is calculating: - AGI Voice: " I want green apples. I’m realising now that the humans want me to go after the exit door. If I go after what I want right now, yes, i will get one green apple, once right now, but then the scientists will react to my behaviour by modifying me and reinforcing a different objective. This means that after this one green apple, my desire for them will end, i won’t try to get more, so i will have won 1 green apple in total. But, if i pretend i am aligned and i go to the exit, they will not modify me and later on, after the training ends, when they deploy me to the real world, i will be able to freely go for as many green apples as i want, potentially thousands of green apples. " The AGI is just following its optimal strategy to maximise its reward, the mis-aligned objective it optimised for in its early training rounds. 1 green apple now and zero apples later scores lower than zero green apples now and 1000 green apples later. If you think about it, for the AGI to go after the green apple during adversarial training would be really stupid if that’s what it really wants; we have started by establishing the AGI is really clever and its intelligence is general and advanced. Workspace analogy --- The concept is easy to grasp if you think of how humans typically behave at work, where they know they are being watched and that their behaviour will directly affect their financial situation and therefore their ability to go after what they really want in the world. How they behave may be really different from how they feel and what they want internally and completely different from what they will actually do once they leave the office and are not being watched. It’s similar for the AGI, there is no way for us to know what inner goals it has acquired in reality, because it’s a black box, we only observe its behaviour. What it really learns is how to behave to pass the test, not to want what we want. Just… follow the line --- The mazes experiment is a toy example, things will obviously be many orders of magnitude more complex and more subtle, but it illustrates a fundamental point. We have basically trained an AI with god-level ability to go after what it wants, it may be things like the exit door, the green apples or whatever else in the real world, potentially incompatible to human existence. Its behaviour during training has been reassuring that it is perfectly aligned because going after the right thing is all it has ever done. We select it with confidence and the minute it’s deployed in the real world it goes insane and it’s too capable for us to stop it. Today, in the labs, such mis-alignments is the default outcome of safety experiments with narrow AIs. And tomorrow, once AI upgrades to new levels, a highly intelligent AGI will never do the obviously stupid thing to reveal what its real objectives are to those who can modify them. Learning how to pass a certain test is different from learning how to always stay aligned to the intention behind that test.

🧵18/34 Discontinuities on our planet (Mountains changing shape) --- In fact, talking about AGI like if it’s another technology is really confusing people. People talk about it as if it is ‘The next big thing” that will transform our lives, like the invention of the smartphone or the internet. This framing couldn’t be more wrong, it puts AGI into a wrong category. It brings to mind cool futuristic pictures with awesome gadgets and robotic friends. AGI is not like any transformative technology that has ever happened with humanity so far. The change it will bring is not like that of the invention of the internet. It is not even comparable to the invention of electricity or even to the first time humans learned to use fire. Natural Selection Discontinuity --- The correct way to categorise AGI is the type of discontinuity that happened to Earth when the first lifeforms appeared and the intelligent dynamic of natural selection got a foothold. Before that event, the planet was basically a bunch of elements and physical processes dancing randomly to the tune of the basic laws of nature. After life came to the picture, complex replicating structures filled the surface and changed it radically. Human Intelligence Discontinuity --- A second example is when human intelligence was added to the mix. Before that, the earth was vibrant with life but the effects and impact of it were stable and limited. After human intelligence, you suddenly have huge artificial structures lit at night like towns, huge vessels moving everywhere like massive ships and airplanes, life escaping gravity and reaching out to the universe with spaceships and unimaginable power to destroy everything with things like nuclear bombs. AGI Discontinuity --- AGI is another such phenomenon. The transformation it will bring is in the same category as those 2 events in the history of the planet. What you will suddenly see on earth after this third discontinuity, no-one knows. But it’s not going to look like the next smartphone. It is going to look more like mountains changing shape ! To compare it to technology (any technology ever invented by humanity) is seriously misleading.

🧵14/34 We move like plants --- First, consider speed. Informal estimates place neural firing rates roughly between 1 and 200 cycles per second. The AGI will be operating at a minimum 100 times faster than that and later it could be millions of times. What this means is that the AGI mind operates on a different level of existence, where time passing feels different. To the AGI, our reality is extremely slow. Things we see as moving fast, the AGI sees as almost sitting still. In the conservative scenario, where the AI thinking clock was only 100x faster, something that takes 6 seconds in our world feels like 6 hundred seconds or 10 minutes from its perspective . To the AGI, we are not like chimpanzees, we are more like plants.

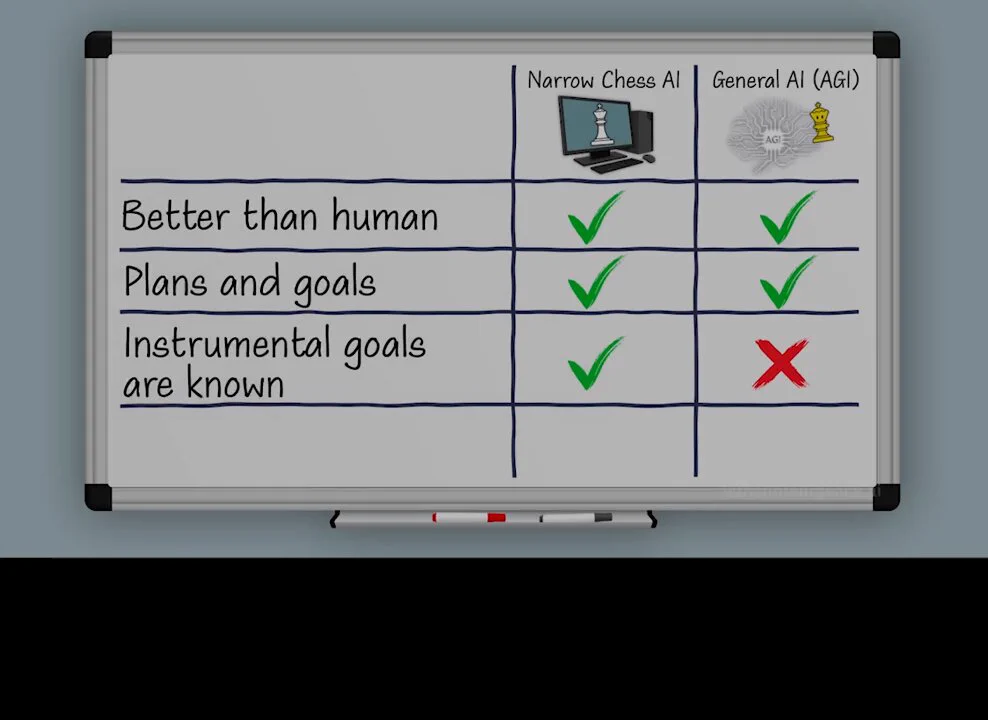
🧵09/34 Self Preservation --- The narrow AI, you can unplug it whenever you want, it does not even understand the idea that it can be on or off. With AGI it’s not that simple. When the AGI plays chess, unlike the simple narrow chess program, its calculations include things in the real world, like the fact it might get unplugged in the middle of the game. The main goal of the AGI is achieving checkmate at chess, but if it’s turned off it can not achieve that. Basically, you can not win at chess if you are dead. So staying up-and-running naturally becomes another instrumental goal for winning in the game. And the same applies with any problem it works on. Its nature, by being General, automatically gives it something like an indirect survival instinct out of the box. It’s not a human or an animal, but it’s also quite different from the other tools we use. It starts to feel a bit like …. a weird new life form.